How to Run Local LLMs with Ollama: Quick Setup Guide


If you've already checked out my guide on running local LLMs with LM Studio, you might be interested in another excellent option: Ollama. This tool offers a streamlined, command-line focused approach to running LLMs locally.
We can also use ollama in our code, integrate with Open WebUI or Continue (VS Code Extension) for a custom cursor IDE-like behaviour. I will publish something on these in the future.
What is Ollama?
Ollama is a lightweight, command-line tool that makes running open-source LLMs locally incredibly simple. It handles model downloads, optimisation, and inference in a single package with minimal configuration needed.
Quick Installation Guide
Windows
- Visit Ollama's official website
- Download and run the Windows installer
- Follow the installation prompts
- Once installed, Ollama runs as a background service
macOS
- Download the macOS app from Ollama's website
- Open the .dmg file
- Drag Ollama to your Applications folder
- Launch the app (it will run in the background)
Linux
Run this command in your terminal:
curl -fsSL https://ollama.com/install.sh | sh
Using Ollama (Basic Commands)
Once installed, using Ollama is as simple as opening a terminal or command prompt and running:
ollama run deepseek-r1:8b
This command downloads the deepseek-r1 8B model (if not already downloaded) and starts an interactive chat session.
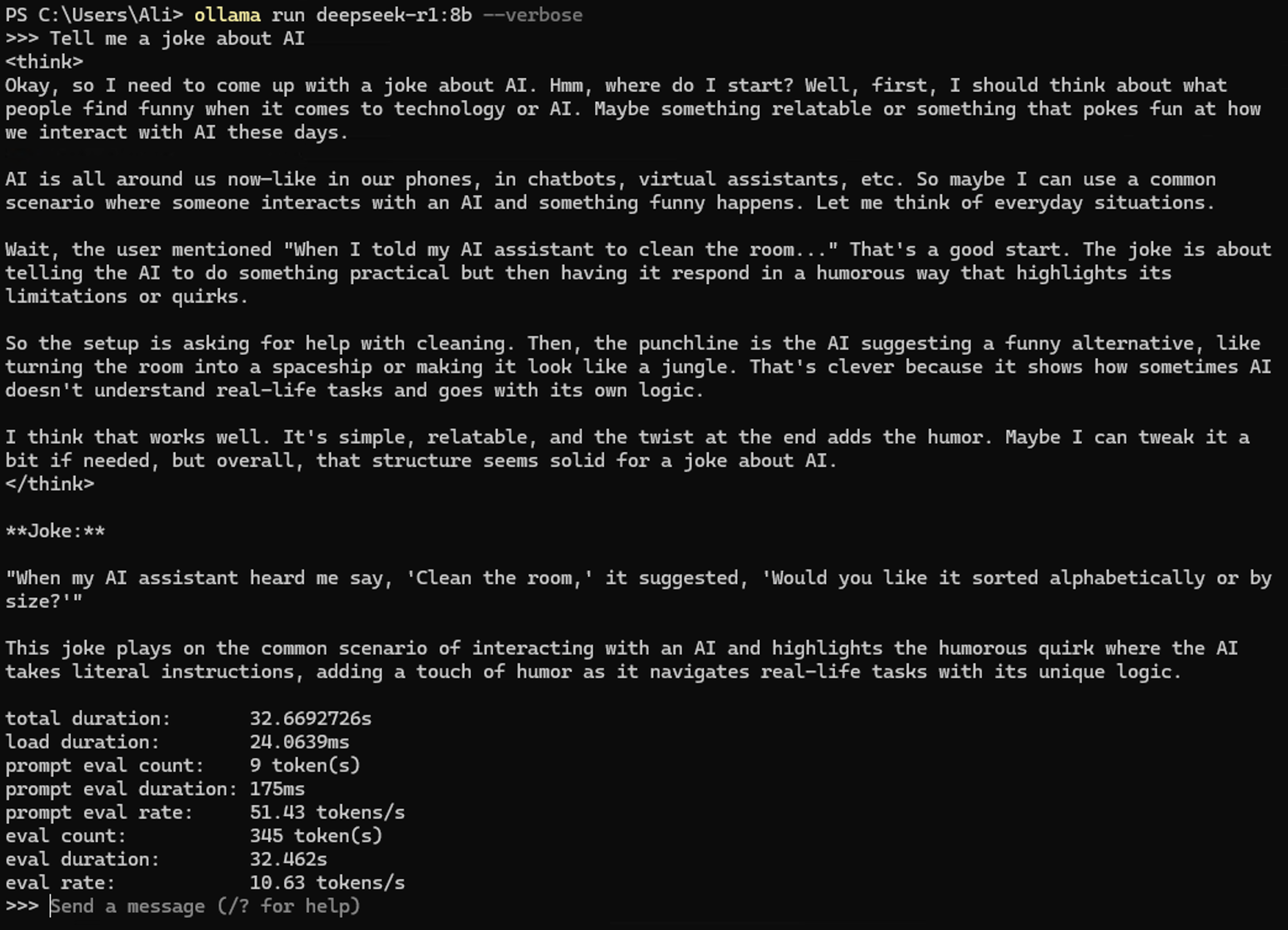
If AI thinks this is funny, then there is a very slim chance of them taking over the world!
If you notice I added a --verbose flag to the run command, this shows us the stats at the end, such as tokens/s.
Popular Models to Try
Ollama makes it easy to experiment with different models:
ollama run llama3 # Meta's latest Llama 3 8B model
ollama run gemma:2b # Google's lightweight Gemma model
ollama run codellama # Specialised for coding tasks
ollama run neural-chat # Optimised for conversation
deepseek-r1:8b # My go to modelTo see all available models:
ollama list remote
To see models you've already downloaded:
ollama list
Hardware Considerations
As explained in my LM Studio article, your hardware still matters. The same considerations apply:
- Smaller models (2B-7B) work on modest hardware
- Larger models (13B+) benefit greatly from a GPU
- At least 16GB RAM recommended for a smooth experience
Ollama will automatically optimise for your available hardware.
Integrating with Other Tools
Ollama works well with several companion tools:
- Open WebUI: A user-friendly chat interface for Ollama
- Continue VS Code Extension: For coding assistance
Integrating with Code
One of Ollama's strongest features is its API, making it easy to integrate into your applications:
Python Integration
import requests
# Simple completion request
response = requests.post('http://localhost:11434/api/generate',
json={
'model': 'deepseek-r1:8b',
'prompt': 'Explain quantum computing in simple terms'
}
)
print(response.json()['response'])JavaScript/Node.js Integration
You can build complete chat applications, coding assistants, or content generation tools using this simple API.
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: 'deepseek-r1:8b',
prompt: 'Write a function to calculate fibonacci numbers'
})
});
const data = await response.json();
console.log(data.response);You can build complete chat applications, coding assistants, AI agents or content generation tools using this simple API. I will be covering this in future posts also.
For More Details
For a deeper dive into running local LLMs, model selection, and optimisation techniques, check out my full guide on running LLMs with LM Studio. The same principles apply, though the interface is different.
Final Thoughts
Ollama offers a more developer-oriented approach to local LLMs compared to LM Studio's GUI-focused experience. It's perfect for those comfortable with the command line or looking to integrate local AI into their development workflows.